Google工作流程
[导读]Google系统的工作流程图 ①Google使用高速的分布式爬行器(Crawler)系统中的漫游遍历器(Googlebot)定时地遍历网页,将遍历到的网页送到存储服务器(Store Server)中。 ②存储服务器使用zlib格式压缩软件将这些网页进行...
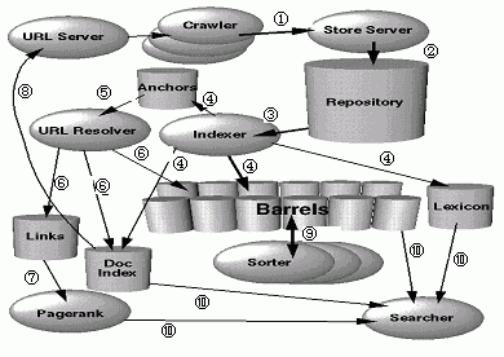
Google系统的工作流程图
①Google使用高速的分布式爬行器(Crawler)系统中的漫游遍历器(Googlebot)定时地遍历网页,将遍历到的网页送到存储服务器(Store Server)中。 ②存储服务器使用zlib格式压缩软件将这些网页进行无损压缩处理后存入数据库Repository (贮藏室)中。Repository获得了每个网页的完全Html代码后,对其压缩后的网页及URL进行分析,记录下网页长度、URL、URL长度和网页内容,并赋予每个网页一个文档号(docID),以便当系统出现故障的时候,可以及时完整地进行网页的数据恢复。 ③索引器(Indexer)从Repository中读取数据,以后做以下四步工作: ④(a)将读取的数据解压缩后进行分析,它将网页中每个有意义的词进行统计后,转化为关键词(wordID)的若干索引项(Hits),生成索引项列表,该列表包括关键词、关键词的位置、关键词的大小和大小写状态等。索引项列表被存入到数据桶(Barrels)中,并生成以文档号(docID)部分排序的顺排档索引。 索引项根据其重要程度分为两种:当索引项中的关键词出现在URL、标题、锚文本(Anchor Text)和标签中时,表示该索引项比较重要,称为特殊索引项(Fancy Hits);其余情况则称为普通索引项(Plain Hits)。在系统中每个Hit用两个字节(byte)存储结构表示:特殊索引项用1位(bit)表示大小写,用二进制代码111(占3位)表示是特殊索引项,其余12位有4位表示特殊索引项的类型(即hit是出现在URL、标题、链接结点还是标签中),剩下8位表示hit在网页中的具体位置;普通索引项是用1位表示大小写,3位表示字体大小,其余12位表示在网页中的具体位置。顺排档索引和Hit的存储结构如图所示。顺排档索引和Hit的存储结构
<!--[if !supportEmptyParas]--> <!--[endif]--> 值得注意的是,当特殊索引项来自Anchor Text时,特殊索引项用来表示位置的信息(8位)将分为两部分:4位表示Anchor Text出现的具体位置,另4位则用来与表示Anchor Text所链接网页的docID相连接,这个docID是由URL Resolver经过转化存入顺排档索引的。 (b)索引器除了对网页中有意义的词进行分析外,还分析网页的所有超文本链接,将其Anchor Text、URL指向等关键信息存入到Anchor文档库中。 (c)索引器生成一个索引词表(Lexicon),它包括两个部分:关键词的列表和指针列表,用于倒排档文档相连接(如图3所示)。 (d)索引器还将分析过的网页编排成一个与Repository相连接的文档索引(Document Index),并记录下网页的URL和标题,以便可以准确查找出在Repository中存储的原网页内容。而且把没有分析的网页传给URL Server,以便在下一次工作流程中进行索引分析。 ⑤URL分析器(URL Resolver)读取Anchor文档中的信息,然后做⑥中的工作。 ⑥(a)将其锚文本(Anchor Text)所指向的URL转换成网页的docID;(b)将该docID与原网页的docID形成“链接对”,存入Link数据库中;(c)将Anchor Text指向的网页的docID与顺排档特殊索引项Anchor Hits相连接。 ⑦数据库Link记录了网页的链接关系,用来计算网页的PageRank值。 ⑧文档索引(Document Index)把没有进行索引分析的网页传递给URL Server,URL Server则向Crawler提供待遍历的URL,这样,这些未被索引的网页在下一次工作流程中将被索引分析。 ⑨排序器(Sorter)对数据桶(Barrels)的顺排档索引重新进行排序,生成以关键词(wordID)为索引的倒排档索引。倒排档索引结构如图所示: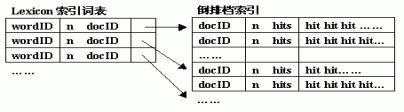
倒排档索引结构
⑩将生成的倒排档索引与先前由索引器产生的索引词表(Lexicon)相连接产生一个新的索引词表供搜索器(Searcher)使用。搜索器的功能是由网页服务器实现的,根据新产生的索引词表结合上述的文档索引(Document Index)和Link数据库计算的网页PageRank值来匹配检索。在执行检索时,Google通常遵循以下步骤(以下所指的是单个检索词的情况): (1)将检索词转化成相应的wordID; (2)利用Lexicon,检索出包含该wordID的网页的docID; (3)根据与Lexicon相连的倒排档索引,分析各网页中的相关索引项的情况,计算各网页和检索词的匹配程度,必要时调用顺排档索引; (4)根据各网页的匹配程度,结合根据Link产生的相应网页的PageRank情况,对检索结果进行排序; (5)调用Document Index中的docID及其相应的URL,将排序结果生成检索结果的最终列表,提供给检索用户。 用户检索包含多个检索词的情况与以上单个检索词的情况类似:先做单个检索词的检索,然后根据检索式中检索符号的要求进行必要的布尔操作或其他操作。
- 转载请注明来源:IT学习网 网址:http://www.t086.com/ 向您的朋友推荐此文章
- 特别声明: 本站除部分特别声明禁止转载的专稿外的其他文章可以自由转载,但请务必注明出处和原始作者。文章版权归文章原始作者所有。对于被本站转载文章的个人和网站,我们表示深深的谢意。如果本站转载的文章有版权问题请联系我们,我们会尽快予以更正。