基于MySQL和Infobright的数据仓库技术
Kicking the Tires
使用Infobright创建表时,操作与任何其他MySQL引擎是大致相同的-所有你要做的就是指定引擎的类型为brighthouse。例如:
mysql> create table t (c1 int) engine=brighthouse;
Query OK, 0 rows affected (0.02 sec)
mysql> insert into t values (1), (2), (3);
Query OK, 3 rows affected (0.16 sec)
Records: 3 Duplicates: 0 Warnings: 0
mysql> select * from t;
+------+
| c1 |
+------+
| 1 |
| 2 |
| 3 |
+------+
3 rows in set (0.00 sec)
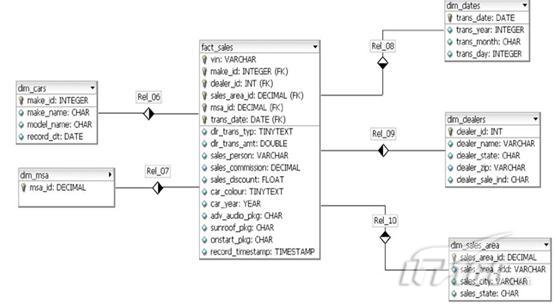
所以,现在进入实际测试:我用作下面查询的模型是一个标准的数据仓库星型模型(代表汽车销售数据库) ,可用如下数据模型描述:
计算行数和数据库的总体规模(如计算INFORMATION_SCHEMA信息)如下:
+----------------------------+-------------+------------+--------------+
| table_name | engine | table_rows | data_length |
+----------------------------+-------------+------------+--------------+
| fact_sales5 | BRIGHTHOUSE | 8080000000 | 135581094511 |
| fact_sales | BRIGHTHOUSE | 1000000000 | 16789624027 |
| fact_sales1b | BRIGHTHOUSE | 1000000000 | 17424704919 |
| mthly_sales_by_dealer_make | BRIGHTHOUSE | 4207788 | 43958330 |
| dim_vins | BRIGHTHOUSE | 2800013 | 15251819 |
| dim_sales_area | BRIGHTHOUSE | 32765 | 302326 |
| dim_dates | BRIGHTHOUSE | 4017 | 9511 |
| dim_dealers | BRIGHTHOUSE | 1000 | 9631 |
| dim_dealers2 | BRIGHTHOUSE | 1000 | 10222 |
| dim_cars | BRIGHTHOUSE | 400 | 4672 |
| dim_msa | BRIGHTHOUSE | 371 | 3527 |
| tt | BRIGHTHOUSE | 1 | 193 |
+----------------------------+-------------+------------+--------------+
12 rows in set (0.00 sec)
+------------------+
| sum(data_length) |
+------------------+
| 169854973688 |
+------------------+
1 row in set (0.01 sec)
上述表明了几个相当大的实表,每个都有10亿行,一个更大的历史实表超过80亿行,一个中型汇总表( 400万行) ,以及一定数量的维数表,其大小是相当小的(除280万行dim_vins表) 。数据库的总物理大小几乎是170GB ,但实际原始数据的大小是1TB,所以你可以看到在Infobright压缩操作中,它做到了它所承诺的。
检查一些行数证明上述数据:
mysql> select count(*) from fact_sales5;
+------------+
| count(*) |
+------------+
| 8080000000 |
+------------+
1 row in set (0.00 sec)
mysql> select count(*) from fact_sales;
+------------+
| count(*) |
+------------+
| 1000000000 |
+------------+
1 row in set (0.00 sec)
请注意, Infobright响应时间就像MyISAM全表做COUNT(*)查询的时间;知识网格知道每个表有多少行,因此你不会浪费时间等待此种查询的答复。
现在,让我们进行几个解析查询,看看我们获得什么。首先,让我们做一个简单操作,看经销商在一个特定的时间内能够销售多少汽车:
mysql> select sum(dlr_trans_amt)
-> from fact_sales a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (24.98 sec)
Not too bad at all. But now let’s put the knowledge grid / data packs to the test and see how big a dent in our response time we get by adding eight times more data to the mix:
这还不算太糟糕。但是,现在让我们把知识网格/数据包进行测试,我们通过曾加八倍以上的数据组合,然后看我们的响应时间受到多大影响。
mysql> select sum(dlr_trans_amt)
-> from fact_sales5 a, dim_cars b
-> where a.make_id = b.make_id and
-> b.make_name = 'ACURA' and
-> b.model_name = 'MDX' and
-> trans_date between '2007-01-01' and '2007-01-31';
+--------------------+
| sum(dlr_trans_amt) |
+--------------------+
| 11264027726 |
+--------------------+
1 row in set (27.20 sec)
非常棒! Infobright能-再次-只审查所需的数据包,并排除所有其他数据,那些他并不需要查找以满足我们的查询,对整体的响应时间并没有真正实际的影响(运行相同的查询但实际上用比第一次查询更小的表) 。
现在,让我们测试,在某些情况下能使普通MySQL服务器瘫痪的查询, -嵌套子查询:
mysql> select avg(dlr_trans_amt)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-12-31' and
-> dlr_trans_type = 'SALE' and make_id =
-> (select make_id
-> from dim_cars
-> where make_name = 'ASTON MARTIN' and
-> model_name = 'DB7') and
-> sales_area_id in
-> (select sales_area_id
-> from dim_sales_area
-> where sales_state =
-> (select dealer_state
-> from dim_dealers
-> where dealer_name like 'BHUTANI%'));
+--------------------+
| avg(dlr_trans_amt) |
+--------------------+
| 45531.444471505 |
+--------------------+
1 row in set (50.78 sec)
Infobright plows through the data just fine. What about UNION statements – oftentimes these can cause response issues with MySQL. Let’s try both fact tables this time:
Infobright处理数据是非常的好。关于联合声明-这些操作往往会造成与MySQL响应冲突。那么,这次让我们尝试两种实际表:
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.49 sec)
mysql> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-01-01' and '2007-01-31')
-> union all
-> (select avg(dlr_trans_amt), avg(sales_commission), avg(sales_discount)
-> from fact_sales5
-> where trans_date between '2007-02-01' and '2007-02-28');
+--------------------+-----------------------+---------------------+
| avg(dlr_trans_amt) | avg(sales_commission) | avg(sales_discount) |
+--------------------+-----------------------+---------------------+
| 45550.1568209903 | 5.39966 | 349.50289769532 |
| 45549.5774942714 | 5.39976 | 349.498835301098 |
+--------------------+-----------------------+---------------------+
2 rows in set (0.75 sec)
It appears the UNION’s were satisfied via knowledge grid access alone. Next, let’s try a few joins coupled with a having clause and ask for the average Ashton Martin dealer transaction amounts over one year for dealers in the state of Indiana:
看来双方对仅通过知识网格来处理的结果都比较满意。接下来,让我们尝试一些有关条款的加盟,并查询阿什顿马丁经销商过去一年对印第安纳州交易商的平均交易金额,:
mysql> select fact.dealer_id,
-> avg(fact.dlr_trans_amt)
-> from fact_sales fact
-> inner join dim_cars cars on (fact.make_id = cars.make_id)
-> inner join dim_sales_area sales on
-> (fact.sales_area_id = sales.sales_area_id)
-> where fact.trans_date between '2007-01-01' and '2007-12-31' and
-> fact.dlr_trans_type = 'SALE' and
-> cars.make_name = 'ASTON MARTIN' and
-> cars.model_name = 'DB7' and
-> sales.sales_state = 'IN'
-> group by fact.dealer_id
-> having avg(fact.dlr_trans_amt) > 50000
-> order by fact.dealer_id desc;
.
.
.
| 2 | 51739.181818182 |
| 1 | 57964.8 |
+-----------+-------------------------+
317 rows in set (50.66 sec)
当然,还有许多其它的查询,可被测试,但上述将给你Infobright如何执行一些典型的解析式查询的感受。再次,一个伟大的事情是你不必花时间设计索引或制定分割计划,以获得上面展示的性能结果,因为所有这些在Infobright中是完全没有必要的。事实上,引擎只有三个左右的微调参数,并且他们都和内存相关。
- 转载请注明来源:IT学习网 网址:http://www.t086.com/ 向您的朋友推荐此文章
- 特别声明: 本站除部分特别声明禁止转载的专稿外的其他文章可以自由转载,但请务必注明出处和原始作者。文章版权归文章原始作者所有。对于被本站转载文章的个人和网站,我们表示深深的谢意。如果本站转载的文章有版权问题请联系我们,我们会尽快予以更正。